FLUID Forge
The Terraform Moment for Data Products Has Arrived.

Jeff Watson | CEO, Agentics Transformation Ltd | Co-author, FLUID Data Products
The data mesh concept was introduced to the industry in 2019. Five years on, the honest question to ask is: how many enterprises have actually implemented a comprehensive, working data product architecture? The answer is surprisingly few. Gartner estimates that fewer than 20% of organisations that publicly commit to data mesh principles reach meaningful data product maturity. Industry surveys consistently show the same pattern: strong intent, weak execution, and a persistent gap between architectural ambition and engineering reality.
The reason is not a lack of conviction. It is a lack of tooling. Organisations have had frameworks, methodologies, operating model designs, and governance charters. What they have not had is a build system — a production-grade tool that takes a data product definition and manufactures it, consistently, with quality and governance embedded, at the pace required to reach scale.
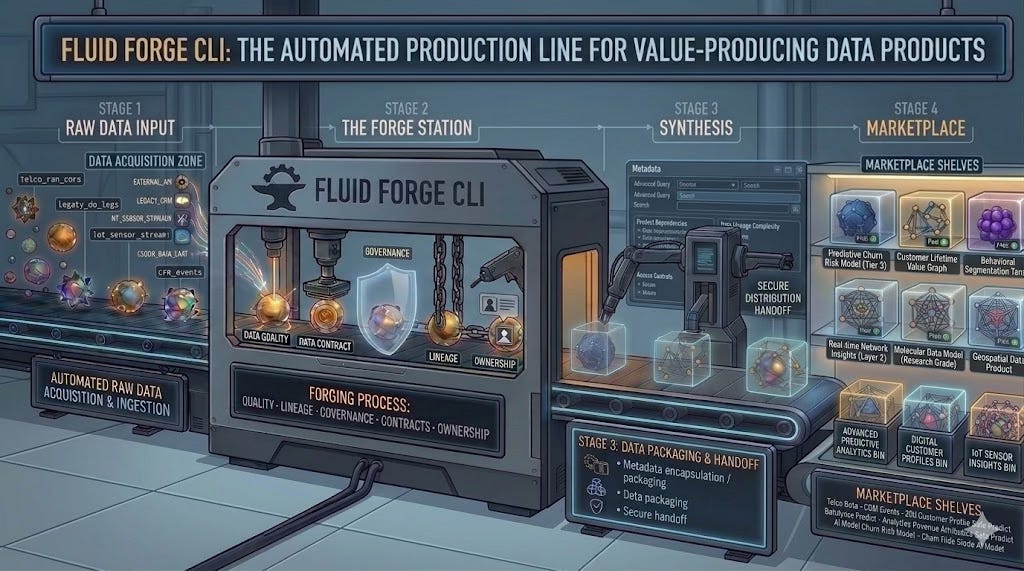
FLUID Forge is a new open-source command-line tool — installable today with a single pip install fluid-forge — that operationalises the FLUID specification (Federated Labelled Universal Interchangeable Declarative) as a complete build system for data products. It turns the theory of data mesh and data product thinking into engineering practice: from a single YAML contract, Forge scaffolds, validates, plans, deploys, governs, tests, and publishes a fully formed data product to your cloud platform of choice. It is the missing link between data strategy and data engineering execution.
The Strategic Problem Forge Solves
Enterprise data transformations consistently stall at the same point: the gap between declaring that data should be treated as a product and actually engineering data products at scale. Consider what building a single data product requires without Forge: a dbt model, a separate Airflow DAG, a Great Expectations quality spec, Snowflake row-level security, catalogue registration, a data contract document, SLA monitoring configuration, and lineage documentation — each in a different tool, a different file format, a different team’s concern, and a different moment of potential inconsistency.
The result is what practitioners know well: data products that exist in name only — undocumented, uncontracted, untested, and ungovernable. The data mesh becomes a data swamp with product labels.
Forge solves this by introducing a single declarative contract — a .fluid.ymlfile — that defines all of these dimensions in one place, with an execution engine that materialises that contract against any cloud provider. Available today as an open-source CLI — pip install fluid-forge along with its companion Forge provider SDK — it is the missing industrial layer between data strategy and data engineering execution.
One file. One command. One data product.
This article makes the case for why it matters strategically, what it does technically, and why the time to act is now.
Five Years of Promise, Limited Delivery
The data mesh pattern has generated extraordinary interest since Zhamak Dehghani’s original formulation. Thousands of organisations have launched transformation programmes, appointed domain data owners, created data product roadmaps, and restructured their data teams around federated ownership. The investment has been substantial.
Yet independent research tells a sobering story. A 2024 survey by TDWI found that fewer than one in four organisations that had formally adopted data mesh had more than ten functioning data products in production. A separate report from DataKitchen found that data quality issues remained the single largest barrier to data product consumption — not a governance failure, but an engineering one. Data products were being declared, not built.
The gap is not philosophical. Every CDO who has tried to industrialise a data product programme has encountered the same friction: engineers spend 60–70% of their time on scaffolding, schema management, pipeline wiring, access policy configuration, and catalogue registration — work that should be automated, not bespoke.
The pattern repeats across industries. Telcos build customer 360 products that take eight months to reach production. Banks create risk exposure products that require four teams to coordinate. Retailers build recommendation products that exist in one environment and cannot be reliably replicated in another. The problem is not ambition — it is the absence of a repeatable, scalable build system.
FLUID Forge is the answer to that absence. By providing a single declarative contract — a .fluid.yml file — and a build system that materialises that contract against any cloud provider, it makes the data product factory concept operational. Not conceptual. Operational.Strategic Power: What a Real Data Product Infrastructure Unlocks
Before examining what Forge does technically, it is worth being precise about what a comprehensive data product infrastructure actually enables strategically. These are not soft benefits — they are measurable competitive capabilities.
Agility: From Months to Days Organisations with mature data product infrastructures respond to market opportunities differently. When a new regulation requires a fresh risk view, or a commercial opportunity demands a new customer segmentation, the question is no longer how long will it take to build the data asset? It is which blueprint do we instantiate? With Forge’s blueprint system, a new data product can be scaffolded, validated, and deployed in hours — not the weeks or months that bespoke engineering requires. This is the difference between being a fast follower and being a laggard.
Innovation: The AI Prerequisite Every serious enterprise AI initiative — recommendation engines, churn prediction, network optimisation, next-best-action — requires trusted, well-described, consistently governed data products as its foundation. Organisations that lack this infrastructure are not slow at AI; they are blocked at AI. Hallucinating models, inconsistent predictions, and untrustworthy outputs are almost always symptoms of data product debt, not model failure. Forge resolves this by ensuring that every data product entering the AI pipeline carries a machine-readable contract, a quality guarantee, and a defined access policy.
Customer Experience: Consistency Across Every Touchpoint The most visible consequence of fragmented data infrastructure is inconsistent customer experience. A customer who receives contradictory information across digital, in-store, and contact centre channels is experiencing the symptom of data products that are not unified, not governed, and not owned. A Customer 360 product built with Forge is defined once, governed consistently, and consumed identically regardless of which channel touches it — because the product is the source of truth, not the channel application.
Governance: From Bureaucracy to Engineering Discipline In most enterprises, data governance is a process applied after the fact — a review gate, a steering committee, a compliance check. This model fails at scale. With Forge, governance is embedded in the contract at the moment of creation: sensitivity classifications, access policies, retention rules, and quality thresholds are declared in the same file that defines the data product itself.
The result is compliance-as-code: auditable, version-controlled, and enforced automatically at build time. For regulated industries — financial services, telecommunications, healthcare — this is not a convenience; it is a material capability that reduces regulatory risk.
The Architecture: One Contract, Any Cloud
The FLUID specification — maintained as an open standard at github.com/open-data-protocol/fluid — defines a data product through a single YAML contract covering identity, ownership, schema, build logic, access policies, SLAs, and lineage. Forge is the build system that executes that contract.
Provider-Agnostic by Design: The End of Vendor Lock-In
One of Forge’s most strategically significant architectural decisions is its provider-agnostic execution model. A data product defined in a .fluid.ymlcontract can be deployed to GCP, AWS, Snowflake, or a local DuckDB environment — by changing a single parameter:
fluid apply contract.fluid.yaml --provider snowflake
fluid apply contract.fluid.yaml --provider gcp
fluid apply contract.fluid.yaml --provider aws
fluid apply contract.fluid.yaml --provider localThe strategic implications of this are profound and deserve emphasis. Organisations that hardcode their data products into a single cloud vendor’s proprietary tooling — Snowflake Tasks, BigQuery Routines, AWS Glue scripts — create architectural debt that becomes extraordinarily expensive to unwind. A data product portfolio of two hundred assets, each tightly coupled to one vendor’s execution environment, cannot be migrated without a multi-year re-engineering programme.
With Forge, the contract is the portable unit. The .fluid.yml file defines what the product is and does. Forge’s provider layer translates that declaration into the execution primitives of whatever cloud platform you are targeting. This means:
▸ Data products built for GCP today can be re-deployed to Snowflake tomorrow without re-engineering the product definition. ▸ Multi-cloud organisations — common in large European enterprises operating across national markets with different cloud footprints — can maintain a single, unified product portfolio that deploys consistently to each environment. ▸ Negotiating leverage with cloud vendors is preserved. The threat of migration is credible, because the cost of migration is low. ▸ Regulatory data residency requirements can be met by deploying to a different regional provider without touching the product definition.
This is not a marginal feature. In an era of cloud consolidation, rising platform costs, and increasing regulatory scrutiny of technology dependencies, the ability to decouple data product definitions from execution environments is a first-order strategic capability.
The FLUID Contract: What It Defines
A minimal contract for a Customer 360 product shows the full scope of what Forge manages in a single file:
fluidVersion: “0.7.1”
kind: DataProduct
id: customer-360-v1
name: Customer 360
domain: Customermetadata:
owner: customer-domain@company.com
layer: Goldexposes:
- name: customer_profile
format: bigquery_table # change to snowflake_table, redshift_table etc.
schema:
- { name: customer_id, type: STRING, sensitivity: internal }
- { name: email, type: STRING, sensitivity: pii }
- { name: lifetime_value, type: FLOAT, sensitivity: confidential }consumes:
- id: crm-events-v2
- id: transaction-history-v1build:
engine: dbt # or spark, sql, dataform
transformation:
pattern: declarativeaccess:
default: internal
grants:
- principal: “group:analytics-team”
rights: [readData, readMetadata]sla:
freshness_hours: 24
availability_percent: 99.5The Core Workflow and Feature Set
The CLI organises into five functional groups. The core workflow follows Terraform’s proven plan/apply model, adapted for data products. Detailed documentation can be found here: https://agentics-rising.github.io/forge_docs/
Command — What it does:
fluid initBootstrap — quickstart, scan existing dbt/Terraform, wizard, or blank
fluid validateSchema + policy compliance check before any execution
fluid planDeterministic execution plan with cost + sovereignty preview
fluid applyFull orchestration: provision → ingest → transform → quality → govern → publish
fluid verifyConfirms deployed state matches contract post-apply
fluid testLive validation against deployed resources; drift detection
fluid policy-checkSensitivity, access, quality, lifecycle, schema evolution enforcement
fluid diffContinuous compliance monitoring: contract vs reality
fluid forgeAI copilot / domain agent / blueprint-driven product creation
fluid scaffold-ciGenerates GitHub Actions / GitLab CI pipeline from contract
fluid exportExports to Airflow DAG, Dagster pipeline, Prefect flow
fluid export-opdsExports to ODPS v4.1, ODCS v3.1, Bitol open standards
The fluid apply command is the orchestration engine. It executes eight sequential phases: validate → provision → ingest → transform → quality gates → govern → monitor → publish. Each phase supports rollback strategies (none, immediate, phase-complete, full-rollback), parallel execution, and metrics export to Prometheus, Datadog, or CloudWatch. For production deployments with full safety:
fluid apply prod-contract.fluid.yaml \
--env production \
--rollback-strategy immediate \
--require-approval \
--backup-state \
--parallel-phases \
--notify slack:data-teamThe fluid-provider-sdk: Building the Ecosystem
The companion fluid-provider-sdk (pip install fluid-provider-sdk) defines the contract that all FLUID providers implement. It is deliberately minimal — zero runtime dependencies, Python 3.9+ — so it embeds cleanly into any environment. The BaseProvider abstract class requires only two methods:
from fluid_provider_sdk import BaseProvider, ApplyResultclass MyCloudProvider(BaseProvider):
name = “mycloud” def plan(self, contract: dict) -> list[dict]:
# Derive normalised actions from the FLUID contract
... def apply(self, actions) -> ApplyResult:
# Execute against MyCloud APIs; return success/failure
...The SDK includes typed ProviderCapabilities (planning, apply, rollback, cost estimation, lineage, streaming), ContractHelper for extracting ExposeSpec/ConsumeSpec/BuildSpec sections, and a full testing harness. Any cloud vendor, data platform, or enterprise platform team can build a FLUID-compliant provider that slots into the same CLI and contract model — making Forge extensible far beyond its current native providers.
Agentic Readiness: The Data Foundation AI Actually Needs
Every enterprise AI deployment ultimately rests on a data question: can agents find and trust the data they need? FLUID contracts are machine-readable data product descriptions. An AI agent querying a FLUID-compliant catalogue can read the contract and know: what data this product contains, at what schema, with what quality guarantees, under what access conditions, with what freshness SLA, and with what lineage from source.
The FLUID specification explicitly frames itself as the foundational layer that makes an organisation MCP-ready — where MCP (Model Context Protocol) is the emerging standard for agent-to-tool communication. While MCP standardises how agents communicate, FLUID standardises the data products they communicate with. Forge is the build system that creates and maintains those products.
For enterprises simultaneously running data transformation programmes and beginning to deploy agentic AI, Forge is doubly relevant: it accelerates the data product programme while building the data substrate that makes AI agents reliable. These are not separate initiatives. They are the same initiative, and Forge is the engineering bridge.
Start Now: The Five-Minute Path to Your First Data Product
Forge installs in seconds and runs entirely locally using DuckDB — no cloud account needed for initial exploration. The fastest path from zero to a running data product:
# 1. Install
pip install fluid-forge#
# 2. Bootstrap a working example with sample data
fluid init my-first-product --quickstart
# 3. Validate the contract
fluid validate contract.fluid.yaml
# 4. Preview - no execution yet
fluid plan contract.fluid.yaml
# 5. Deploy locally (DuckDB, no cloud required)
fluid apply contract.fluid.yaml --yes
# 6. Migrate an existing dbt project
fluid init --scan ./existing-dbt-project --provider snowflake
# 7. Use AI to guide product creation
fluid forge --mode copilot# Providers for GCP, AWS, and Snowflake activate by changing the --providerflag. Existing dbt and Terraform investments are not abandoned — the --scan flag imports them into the FLUID model incrementally.
▸ Open-source specification: github.com/open-data-protocol/fluid ▸ Install Forge: pypi.org/project/fluid-forge ▸ Provider SDK: pypi.org/project/fluid-provider-sdk
Conclusion: The Build System the Data Mesh Has Always Needed
Five years into the data mesh movement, the gap between aspiration and delivery is not closing fast enough. The organisations that have succeeded share a common characteristic: they treated data product creation as an engineering discipline, with repeatable tooling, embedded quality, and automated governance — not a consulting exercise or a methodology project.
FLUID Forge provides that engineering discipline. It is declarative, provider-agnostic, governance-embedded, standard-compliant, and agentic-ready. Critically, it is portable: the same data product definition deploys to GCP today, Snowflake tomorrow, and AWS next year — without re-engineering, without vendor lock-in, without architectural debt.
The factory is now open. The question is not whether your organisation needs a data product build system — it does. The question is how long you are willing to wait to use one.
Your first governed, portable data product: in under five minutes.
▸ FLUID Protocol: github.com/open-data-protocol/fluid ▸ Install Forge: pypi.org/project/fluid-forge ▸ Provider SDK: pypi.org/project/fluid-provider-sdk
Jeff Watson is CEO of Agentics Transformation Ltd and co-author of FLUID Data Products: The Enterprise Protocol for Data Context in the Agentic Era. He writes at Agentic Rising on Substack.